| Delphi Clinic | C++Builder Gate | Training & Consultancy | Delphi Notes Weblog | Dr.Bob's Webshop |
| Delphi Clinic | C++Builder Gate | Training & Consultancy | Delphi Notes Weblog | Dr.Bob's Webshop |
| ||||||
Internet file formats can be divided into a few groups. First, we have the file transfer (or communication) file formats, for which a long time ago the uuencode/decode schema was invented, followed by xxencode/decode. This later evolved into the base64 encoding and MIME messaging scheme that a lot of mailers use today. A second type of internet file formats is the Hyper Text Markup Language (HTML), with all its versions and (often browser specific) enhancements a true group in itself. The third group of internet file formats is more an interface or protocol of communication again; the Common Gateway Interface (CGI), of which we can identify standard (or console) CGI and Windows CGI or WinCGI.
Internet File Transfer
Delphi is extremely suited to write new components, and to illustrate uuencode/uudecode, xxencode/xxdecode and base64 encoding, we'll write a powerful component that implement these algorithms.
The new component will implement the uuencode and uudecode file conversion algorithms that can be used to transfer files on the internet (previously used in unix-to-unix file transfers).
For a more sophisticated way of transfering files from one point to another, see the chapter about WININET and the FTP (File Transfer Protocol) component.
The file transfer encoding algorithms presented here are mainly used in e-mail and newsgroup environments.
UUEncode and UUDecode
The objective of uuencoding is to encode a file which may contain any "binary" characters into another file with a standard "readable" (or printable) character set of 64 characters being: [`!"#$%&'()*+,-./0123456789:;<=>?@ABC...XYZ[\]^_], so that the encoded file can be reliably sent over diverse networks and e-mail gates.
The 64 printable uuencode characters can be presented in a table as follows:
0 ` | 8 ( | 16 0 | 24 8 | 32 @ | 40 H | 48 P | 56 X |
1 ! | 9 ) | 17 1 | 25 9 | 33 A | 41 I | 49 Q | 57 Y |
2 " | 10 * | 18 2 | 26 : | 34 B | 42 J | 50 R | 58 Z |
3 # | 11 + | 19 3 | 27 ; | 35 C | 43 K | 51 S | 59 [ |
4 $ | 12 , | 20 4 | 28 < | 36 D | 44 L | 52 T | 60 \ |
5 % | 13 - | 21 5 | 29 = | 37 E | 45 M | 53 U | 61 ] |
6 & | 14 . | 22 6 | 30 > | 38 F | 46 N | 54 V | 62 ^ |
7 ' | 15 / | 23 7 | 31 ? | 39 G | 47 O | 55 W | 63 _ |
procedure Triplet2Kwartet(const Triplet: TTriplet;
var Kwartet: TKwartet);
var
i: Integer;
begin
Kwartet[0] := (Triplet[0] SHR 2);
Kwartet[1] := ((Triplet[0] SHL 4) AND $30) +
((Triplet[1] SHR 4) AND $0F);
Kwartet[2] := ((Triplet[1] SHL 2) AND $3C) +
((Triplet[2] SHR 6) AND $03);
Kwartet[3] := (Triplet[2] AND $3F);
for i:=0 to 3 do
if Kwartet[i] = 0 then
Kwartet[i] := $40 + Ord(SP)
else Inc(Kwartet[i], Ord(SP))
end {Triplet2Kwartet};
This routine consists of two parts: in the first part, the 24 bits (3 * 8) from the Triplet is spread out over the 24-bits (4 * 6) of the Kwartet.
In the second part of the algorithm, we add the ASCII value of the space character to each Kwartet.
The ASCII space character is coded as Ord(SP), where SP is defined as the space character or #32.
Note that in case the Kwartet has a value of zero, we don't just add the space character to it.
That would mean that the encoded character is a whitespace, and many mailers have trouble sending multiple whitespaces or trailing whitespaces on body lines.
Hence, in those cases the value 64 (or $40) is also added to the Kwartet, resulting not in a whitespace but in the back-quote ` character.
The value $40 will be neutralized by the uudecode algorithm, so it doesn't really matter to a decent uudecoder whether or not we've used a whitespace or a back-quote at all.
procedure Kwartet2Triplet(const Kwartet: TKwartet;
var Triplet: TTriplet);
var
i: Integer;
begin
Triplet[0] := ((Kwartet[0] - Ord(SP)) SHL 2) +
(((Kwartet[1] - Ord(SP)) AND $30) SHR 4);
Triplet[1] := (((Kwartet[1] - Ord(SP)) AND $0F) SHL 4) +
(((Kwartet[2] - Ord(SP)) AND $3C) SHR 2);
Triplet[2] := (((Kwartet[2] - Ord(SP)) AND $03) SHL 6) +
((Kwartet[3] - Ord(SP)) AND $3F)
end {Kwartet2Triplet};
If the size of a Triplet in the file to encode (or Kwartet in the file to decode) is not exact the 3 Byte size of the Triplet (or 4 Byte size of the Kwartet), then zero's are added as extra characters to fill the structure to encode or decode.
XXEncode and XXDecode
Uuencoding has been the most popular form of base64 encoding.
Limitations of uuencoding is that character sets do not translate well between ASCII and EBCDIC (IBM mainframe).
Xxencoding is very similar to uuencoding, but only uses a different character set than uuencoding so that character set translations will work better across multiple types of systems, i.e.
between the above specified EBCDIC and ASCII.
0 + | 8 6 | 16 E | 24 M | 32 U | 40 c | 48 k | 56 s |
1 - | 9 7 | 17 F | 25 N | 33 V | 41 d | 49 l | 57 t |
2 0 | 10 8 | 18 G | 26 O | 34 W | 42 e | 50 m | 58 u |
3 1 | 11 9 | 19 H | 27 P | 35 X | 43 f | 51 n | 59 v |
4 2 | 12 A | 20 I | 28 Q | 36 Y | 44 g | 52 o | 60 w |
5 3 | 13 B | 21 J | 29 R | 37 Z | 45 h | 53 p | 61 x |
6 4 | 14 C | 22 K | 30 S | 38 a | 46 i | 54 q | 62 y |
7 5 | 15 D | 23 L | 31 T | 39 b | 47 j | 55 r | 63 z |
const
XX: Array[0..63] of Char =
'+-0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz';
procedure Triplet2Kwartet(const Triplet: TTriplet;
var Kwartet: TKwartet);
var
i: Integer;
begin
Kwartet[0] := (Triplet[0] SHR 2);
Kwartet[1] := ((Triplet[0] SHL 4) AND $30) +
((Triplet[1] SHR 4) AND $0F);
Kwartet[2] := ((Triplet[1] SHL 2) AND $3C) +
((Triplet[2] SHR 6) AND $03);
Kwartet[3] := (Triplet[2] AND $3F);
for i:=0 to 3 do
if Kwartet[i] = 0 then
Kwartet[i] := $40 + Ord(SP)
else Inc(Kwartet[i],Ord(SP));
if XXCode then
for i:=0 to 3 do
Kwartet[i] := Ord(XX[(Kwartet[i] - Ord(SP)) mod $40])
end {Triplet2Kwartet};
The last few lines of the Triplet2Kwartet routine are new, and use the XX character set to return the right encoded character.
Remember that the uuencoding algorithm returns the index of the encoded character, after which we add the value of a whitespace, so if the xxencode algorithm is performed after the general uuencode algorithm, we must subtract the value of whitespace again and use the remainder as index in the XX character array.
procedure Kwartet2Triplet(Kwartet: TKwartet;
var Triplet: TTriplet);
var
i: Integer;
begin
if XXCode then
begin
for i:=0 to 3 do
begin
case Chr(Kwartet[i]) of
'+': Kwartet[i] := 0 + Ord(SP);
'-': Kwartet[i] := 1 + Ord(SP);
'0'..'9': Kwartet[i] := 2 + Kwartet[i]
- Ord('0') + Ord(SP);
'A'..'Z': Kwartet[i] := 12 + Kwartet[i]
- Ord('A') + Ord(SP);
'a'..'z': Kwartet[i] := 38 + Kwartet[i]
- Ord('a') + Ord(SP)
end
end
end;
Triplet[0] := ((Kwartet[0] - Ord(SP)) SHL 2) +
(((Kwartet[1] - Ord(SP)) AND $30) SHR 4);
Triplet[1] := (((Kwartet[1] - Ord(SP)) AND $0F) SHL 4) +
(((Kwartet[2] - Ord(SP)) AND $3C) SHR 2);
Triplet[2] := (((Kwartet[2] - Ord(SP)) AND $03) SHL 6) +
((Kwartet[3] - Ord(SP)) AND $3F)
end {Kwartet2Triplet};
Note that in the new versions of the above two routines a global boolean variable "XXCode" is used to determine whether or not we're performing the xxencoding/decoding or the plain uuencoding/decoding algorithm.
Base64
The base64 encoding algorithm is different from the uuencode and xxencode algorithms, in that no first "count" character is used on the body lines.
It is similar to the uuencode and xxencode algorithms in that it converts Triplets into Kwartets using a 64 printable character conversion table.
0 A | 8 I | 16 Q | 24 Y | 32 g | 40 o | 48 w | 56 4 |
1 B | 9 J | 17 R | 25 Z | 33 h | 41 p | 49 x | 57 5 |
2 C | 10 K | 18 S | 26 a | 34 I | 42 q | 50 y | 58 6 |
3 D | 11 L | 19 T | 27 b | 35 j | 43 r | 51 z | 59 7 |
4 E | 12 M | 20 U | 28 c | 36 k | 44 s | 52 0 | 60 8 |
5 F | 13 N | 21 V | 29 d | 37 l | 45 t | 53 1 | 61 9 |
6 G | 14 O | 22 W | 30 e | 38 m | 46 u | 54 2 | 62 + |
7 H | 15 P | 23 X | 31 f | 39 n | 47 v | 55 3 | 63 / |
const
B64: Array[0..63] of Char =
'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/';
procedure Triplet2Kwartet(Const Triplet: TTriplet;
var Kwartet: TKwartet);
var
i: Integer;
begin
Kwartet[0] := (Triplet[0] SHR 2);
Kwartet[1] := ((Triplet[0] SHL 4) AND $30) +
((Triplet[1] SHR 4) AND $0F);
Kwartet[2] := ((Triplet[1] SHL 2) AND $3C) +
((Triplet[2] SHR 6) AND $03);
Kwartet[3] := (Triplet[2] AND $3F);
for i:=0 to 3 do
if Kwartet[i] = 0 then
Kwartet[i] := $40 + Ord(SP)
else Inc(Kwartet[i],Ord(SP));
if Base64 then
for i:=0 to 3 do
Kwartet[i] := Ord(B64[(Kwartet[i] - Ord(SP)) mod $40])
else
if XXCode then
for i:=0 to 3 do
Kwartet[i] := Ord(XX[(Kwartet[i] - Ord(SP)) mod $40])
end {Triplet2Kwartet};
procedure Kwartet2Triplet(Kwartet: TKwartet;
var Triplet: TTriplet);
var
i: Integer;
begin
if Base64 then
begin
for i:=0 to 3 do
begin
case Chr(Kwartet[i]) of
'A'..'Z': Kwartet[i] := 0 + Kwartet[i]
- Ord('A') + Ord(SP);
'a'..'z': Kwartet[i] := 26+ Kwartet[i]
- Ord('a') + Ord(SP);
'0'..'9': Kwartet[i] := 52+ Kwartet[i]
- Ord('0') + Ord(SP);
'+': Kwartet[i] := 62+ Ord(SP);
'/': Kwartet[i] := 63+ Ord(SP);
end
end
end
else
if XXCode then
begin
for i:=0 to 3 do
begin
case Chr(Kwartet[i]) of
'+': Kwartet[i] := 0 + Ord(SP);
'-': Kwartet[i] := 1 + Ord(SP);
'0'..'9': Kwartet[i] := 2 + Kwartet[i]
- Ord('0') + Ord(SP);
'A'..'Z': Kwartet[i] := 12 + Kwartet[i]
- Ord('A') + Ord(SP);
'a'..'z': Kwartet[i] := 38 + Kwartet[i]
- Ord('a') + Ord(SP)
end
end
end;
Triplet[0] := ((Kwartet[0] - Ord(SP)) SHL 2) +
(((Kwartet[1] - Ord(SP)) AND $30) SHR 4);
Triplet[1] := (((Kwartet[1] - Ord(SP)) AND $0F) SHL 4) +
(((Kwartet[2] - Ord(SP)) AND $3C) SHR 2);
Triplet[2] := (((Kwartet[2] - Ord(SP)) AND $03) SHL 6) +
((Kwartet[3] - Ord(SP)) AND $3F)
end {Kwartet2Triplet};
Note that in the new versions of the above two routines a new global boolean variable "Base64" is used to determine whether or not we're performing the base64encoding/decoding or the uu/xx-encoding/decoding algorithm.
MIME
MIME stands for Multipurpose Internet Mail Extensions, which is the latest international standard for base64 encoding.
It was designed to handle multiple language support and character translations across multiple types of systems (such as IBM mainframes, UNIX systems, and Macintosh and IBM PC's).
MIME is an encoding algorithm described in RFC1341 as MIME base64.
Like uuencode, the purpose of MIME is to encode binary files into ASCII so that they may be passed through e-mail gates, and MIME uses the base64 algorithm for that, plus a set of additional keywords and options which can be used to specify more detailed information about the contents of the encoded document.
MIME will be covered in some more detail in the MAIL chapter by John Kaster.
TBUUCode Component
The interface definition of the entire TUUCode component, based on the previously defined and underlying Triplet2Kwartet and Kwartet2Triplet routines, is defined as follows (note that this code compiles with all versions of Delphi and C++Builder):
unit UUCode;
interface
uses
{$IFDEF WIN32}
Windows,
{$ELSE}
WinTypes, WinProcs,
{$ENDIF}
SysUtils, Messages, Classes, Graphics, Controls, Forms;
{$IFNDEF WIN32}
type
ShortString = String;
{$ENDIF}
type
EUUCode = class(Exception);
TAlgorithm = (filecopy, uuencode, uudecode,
xxencode, xxdecode,
base64encode, base64decode);
TUnixCRLF = (CRLF, LF);
TProgressEvent = procedure(Percent:Word) of Object;
TBUUCode = class(TComponent)
public
{ Public class declarations (override) }
constructor Create(AOwner: TComponent); override;
private
{ Private field declarations }
FAbout: ShortString;
FActive: Boolean;
FAlgorithm: TAlgorithm;
FFileMode: Word;
FHeaders: Boolean;
FInputFileName: TFileName;
FOutputFileName: TFileName;
FOnProgress: TProgressEvent;
FUnixCRLF: TUnixCRLF;
{ Dummy method to get read-only About property }
procedure Dummy(Ignore: ShortString);
protected
{ Protected Activate method }
procedure Activate(GoActive: Boolean);
public
{ Public UUCode interface declaration }
procedure UUCode;
published
{ Published design declarations }
property About: ShortString read FAbout write Dummy;
property Active: Boolean read FActive write Activate;
property Algorithm: TAlgorithm read Falgorithm
write FAlgorithm;
property FileMode: Word read FFileMode write FFileMode;
property Headers: Boolean read FHeaders write FHeaders;
property InputFile: TFileName read FInputFileName
write FInputFileName;
property OutputFile: TFileName read FOutputFileName
write FOutputFileName;
property UnixCRLF: TUnixCRLF read FUnixCRLF write FUnixCRLF;
published
{ Published Event property }
property OnProgress: TProgressEvent read FOnProgress
write FOnProgress;
end {TUUCode};
Properties
The TUUCode component has eight published properties (we skip the event property for now):
The About property contains the copyright and version information.
The Active property can be used to call the UUCode conversion method at design time, similar to the Active property of TTables and TQuery components.
The Algorithm property contains the specific algorithm to be executed by the UUCode conversion method.
The following algorithms are implemented and supported by the TUUCode component:
Methods
The TUUCode component has three methods; one public constructor, one protected method and one public method:
The public constructor Create is used to create the component and initialize the default property values of Active, FileMode, Headers and About.
The protected method Activate is used to call the public method UUCode at design-time when we set the Active property to True.
It is never necessary to call this method itself directly, since it's much easier to call the public method UUCode.
The public method UUCode is where the encoding and decoding algorithms are actually performed on the InputFile, based on the values of the other properties of the TUUCode component.
Events
The TUUCode component has one event property:
The OnProgress event can be used as callback function to let the TUUCode component specify the current percentage of the InputFile which is encoded or decoded.
Using this information, we can use a 16-bits TGauge or 32-bits TProgressBar component, for example, to show the progress of the encoding or decoding process from 0 to 100%.
Encoding of decoding large documents may take up some time, even if you have a fast machine and hard disk.
Therefore, it could come in handy to have the ability to show the progress of the encoding and decoding process.
To implement this, we need to create a new event, OnProgress, an event signaler and a corresponding event hander.
Events consist of two parts: an event signaler and the event handler.
The signaler must make sure that the component somehow gets a message of some sort to indicate that some condition has become true, and that the event is now born.
The event handler, on the other hand, starts to work only after the event itself is generated, and responds to it by doing some processing of itself.
Event signalers are typically based on virtual (or dynamic) methods of the class itself (like the general Click method) or Windows messages, such as notification or callback messages.
Event handlers are typically placed in event properties, such as the OnClick, OnChange or OnProgress event handler property.
If event handlers are published, then the user of the component can enter some event handling code that is to be executed when the event is fired.
Event Handlers
Event Handlers are methods of type Object.
This means that they can be assigned to class methods, and not to ordinary procedures or functions (the first parameter must be a Self type of thing).
Consider the type TNotifyEvent for the most general of event handlers:
TNotifyEvent = procedure(Sender: TObject) of object;The TNotifyEvent type is the type for events that have only the sender as parameter. These events simply notify the component that a specific event occurred at a specific TObject (the sender). For example, OnClick, which is type TNotifyEvent, notifies the control that a click event occurred on the control Sender. If the parameter Sender would be omitted as well, then we'd only know that a specific event had occurred, but not to which control. Generally, we do want to know for which control the event just occurred, so we can act on the control (or on data in the control).
TProgressEvent = procedure(Percent: Word) of object;
Event Signalers
Event signalers are needed to signal to an event handler that a certain event has occurred, so the event handler can perform its action.
Event signalers are typically based on virtual (or dynamic) methods of the class itself (like the general Click method) or Windows messages, such as callback or notification messages.
In case of the TUUCode component, the event signaler is integrated within the UUCode method itself.
After each line of encoded characters, the OnProgress event is called, if one is present.
In code, this is implemented as follows:
if Assigned(FOnProgress) then
FOnProgress(trunc((100.0 * Size) / OutputBufSize))
Where Size is the current size (or position) of the output buffer that is already encoded or decoded, and OutputBufSize is the expected total filesize of the outputfile.
Size will grow from zero to OutputBufSize, which means that the FOnProgress event handler is called with an argument between 0 and 100.
Registration
When registering the TUUCode component, it helps to add a design-time property editor for the FileName (of the InputFile) to add a little bit more support for the end-user.
This property editor is implemented in the same UUReg unit that registers the TUUCode component in the Delphi Component Palette:
unit UUReg;
interface
{$IFDEF WIN32}
{$R UUCODE.D32}
{$ELSE}
{$R UUCODE.D16}
{$ENDIF}
uses
DsgnIntf;
type
TFileNameProperty = class(TStringProperty)
public
function GetAttributes: TPropertyAttributes; override;
procedure Edit; override;
end;
procedure Register;
implementation
uses
UUCode, { TUUCode }
Classes, Dialogs, Forms, SysUtils;
function TFileNameProperty.GetAttributes: TPropertyAttributes;
begin
Result := [paDialog]
end {GetAttributes};
procedure TFileNameProperty.Edit;
begin
with TOpenDialog.Create(Application) do
try
Title := GetName; { name of property as OpenDialog caption }
Filename := GetValue;
Filter := 'All Files (*.*)|*.*';
HelpContext := 0;
Options := Options +
[ofShowHelp, ofPathMustExist, ofFileMustExist];
if Execute then SetValue(Filename);
finally
Free
end
end {Edit};
procedure Register;
begin
{ component }
RegisterComponents('DrBob42', [TUUCode]);
{ property editor }
RegisterPropertyEditor(TypeInfo(TFilename), nil,
'InputFile', TFilenameProperty);
end {Register};
end.
If we want to use Delphi packages to "package" the TUUCode component (pun intended), then we should put the unit UUCode in a runtime package, and the unit UUReg in a design-time package (that requires the runtime package).
In fact, using packages we can even put the UUCode Wizard from next section in the design-time package and have it available in the IDE of Delphi to all users!
UUCode Example Wizard
The 16-bit example program uses a TGauge component to show the progress of the conversion algorithm, while the 32-bit version uses a Windows 95 Progress Control.
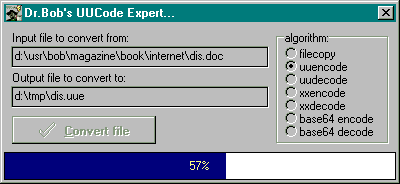
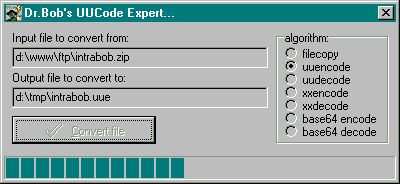
Figure 2: 32-bit Version of the UUCode Example Program
There are two possible exceptions that can be raised by the example programs: if the inputfilename is empty, and - when encoding - if the outputfilename is empty. The 16-bits version can raise a third exception if the inputfile or outputfile is bigger than 65000 characters (the 16-bits version of this component can only handle input and output files up to 64Kb in size. In practice, this means that the input file cannot be bigger than approximately 48Kb. The 32-bit version has no such limitation, of course).
Summary
In this chapter, we've explored the uuencode/uudecode, xxencode/xxdecode, and base64 encode/decode algorithms.
We developed a single VCL component that supports all these algorithms in addition to the simple filecopy.
Properties, methods and events make this component a valuable tool in building internet applications that require these specific file conversions.
The TBUUCode component is now part of the DrBob42 component package for Delphi and C++Builder.


