| Delphi Clinic | C++Builder Gate | Training & Consultancy | Delphi Notes Weblog | Dr.Bob's Webshop |
| Delphi Clinic | C++Builder Gate | Training & Consultancy | Delphi Notes Weblog | Dr.Bob's Webshop |
| ||||||
Suppose you have a database with products. Advertisement on paper is expensive (tell me about it). But advertising on the web is something new and can be relatively cheap. It would be a good start to have your database published on the web, wouldn't it. But setting up your own Site with an NT Web Server running with a tool like IntraBuilder or WebHub will cost you money as well, including time and experience to set it up. This chapter will offer a quick and dirty way to publish the information in your databases on the web: just generate static HTML pages (as opposed to dynamic HTML-pages), based on the record in the tables. Expensive? No. Complex? I don't think so. Let's take a closer look and end up with a little Database HTML Expert that will do the job for us...
Delphi and HTML
My main development tool is Delphi, and we'll be writing a Delphi Database HTML Expert in this chapter.
Delphi will connect to just about any database format.
Natively (using the Borland Database Engine) to Paradox and dBASE, with ODBC to Access for example, and with SQL Links to big DBMSs like InterBase, Oracle, Sybase and Informix.
Also, you can buy an add-on product like Apollo (from SuccessWare) to talk to Clipper and FoxPro tables.
In this chapter, we'll be using the Paradox database format.
Paradox is a very rich database format, so any problems when converting fields, types and values from a database format to HTML will surface here.
Basic HTML
While the input of our converter will be a database table, the output will consist of a set of HTML-pages; the cornerstone of world-wide web publishing these days.
Field Conversion
A HTML page consists of text, plain ASCII text.
Of course, there can be all sorts of things embedded in the text, most usually images in .GIF or .JPEG format.
A database table consists of fields that most often have a value that can be expressed as a String of characters.
Delphi even has the built-in "AsString" property for all classed derived from TField.
The AsString actually is a conversion property.
For a TStringField, AsString can be used to read the value of the field as a string.
For TBCDField, TCurrencyField, TDateField, TDateTimeField, TFloatField, TIntegerField, TSmallintField, TTimeField, and TWordField, AsString converts the type to a string when reading from the field.
For TBooleanField, AsString returns 'T' or 'F'.
For a TMemoField, TGraphicField, TBlobField, TBytesField or TVarBytesField, AsString should only be used to read from the field.
It sets the string value to '(Memo)', '(Graphic)', '(Blob)', '(Bytes)' or '(Var Bytes)' resp. when reading from the field.
Since memo fields can contain important textual information that must be included, I've chosen to ignore all but the TMemoField, and when working with TMemoField we can use the SaveToStream method to read from a field, as we will see later.
So, we can distinguish two groups: those who can convert their data to a textual format using the AsString property, and those who can't.
We can define a third type (unknown), and come up with the following code definitions for a table with up to 255 fields:
const
MaxField = 255;
sf_UnKnown = 0;
sf_String = 1;
sf_Memo = 2;
var
FieldTypes: Array[0..Pred(MaxField)] of Byte; { default unknowns }
We need to go through the structure of the Table to obtain the field type information, as follows:
with TTable.Create(nil) do
try
DatabaseName := ADatabase;
TableName := ATable;
Active := True;
keys := -1; { no key in table }
for i:=0 to Pred(FieldDefs.Count) do
begin
if Fields[i].IsIndexField then keys := i;
FieldTypes[i] := sf_String; { default }
if (FieldDefs[i].FieldClass = TMemoField) then
FieldTypes[i] := sf_Memo
else
if (FieldDefs[i].FieldClass = TGraphicField) or
(FieldDefs[i].FieldClass = TBlobField) or
(FieldDefs[i].FieldClass = TBytesField) or
(FieldDefs[i].FieldClass = TVarBytesField) then
FieldTypes[i] := sf_UnKnown { ignore }
end
finally
Free
end;
Records
After the analysis of the fields of the table, we can actually walk through the entire table and get the values of the fields.
For each record in the table, we can generate a HTML-page.
We use the fieldnames as a header, using <H2> for key-fields and the somewhat smaller <H3>-headers for non-key fields.
The code to walk through the table and convert the fields in all records to text and write it out in a HTML-file, is as follows:
while not Eof do
begin
Inc(RecNr);
System.Assign(f,FileName+'/'+PageNr(RecNr));
System.Rewrite(f);
writeln(f,'<HTML>');
writeln(f,'<HEADER>');
writeln(f,'<TITLE>');
writeln(f,Format('%s %d/%d',[ATable,RecNr,RecordCount]));
writeln(f,'</TITLE>');
writeln(f,'</HEADER>');
writeln(f,'<BODY>');
{ print fields }
for i:=0 to Pred(FieldCount) do if FieldTypes[i] > sf_UnKnown then
begin
if (keys >= i) then writeln(f,'<H2>')
else writeln(f,'<H3>');
writeln(f,FieldDefs[i].Name,':');
if (keys >= i) then writeln(f,'</B><BR>') { </H2> }
else writeln(f,'</B><BR>'); { </H3> }
if FieldTypes[i] = sf_Memo then
writeMemo(f,Fields[i])
else writeln(f,Fields[i].AsString);
if (keys = i) then writeln(f,'<HR>');
end;
writeln(f,'</BODY>');
writeln(f,'</HTML>');
System.Close(f);
Next
end;
Note that I've used an undocumented HTML-feature here: to end a header, you can write </B>, but you must use a <BR> to insert a break and move to the next line.
This way, you can have headers, and text that starts right under the header, without the trailing while space (sometimes up to a full line of text) that you normally get.
Please note that this is a undocumented feature, so you should replace it by the commented </H2> and </H3> if you don't want to live on the edge <grin>
The following listing shows how we get the information out of a memo field in the database and into a text file.
And while we're at it, we format it a little bit (remember that HTML ignores linefeeds and multiple white spaces)...
procedure WriteStream(var f: Text; var Stream: TMemoryStream);
const
LF = #10;
BufSize = 8192; { bigger memos are chopped off!! }
var
Buffer: Array[0..Pred(BufSize)] of Char;
i: Integer;
begin
Stream.Seek(0,0);
if Stream.Size > 0 then
begin
Stream.Read(Buffer,Stream.Size);
for i:=0 to Pred(Pred(Stream.Size)) do
begin
{ empty line converted to <P> break }
if (Buffer[i] = LF) and (Buffer[i+1] = LF) then writeln(f,'<P>');
{ strip multiple spaces (are ignored anyway) }
if not ((Buffer[i] = ' ') and (Buffer[i+1] = ' ')) then write(f,Buffer[i]);
{ start new sentence on a new line (but only in HTML doc itself }
if (Buffer[i] = '.') and (Buffer[i+1] = ' ') then writeln(f)
end;
writeln(f,Buffer[Pred(Stream.Size)])
end
else writeln(f,' ') { empty memo }
end {WriteStream};
procedure WriteMemo(var f: Text; Field: TField);
var Stream: TMemoryStream;
begin
Stream := TMemoryStream.Create;
(Field AS TMemoField).SaveToStream(Stream);
WriteStream(f,Stream);
Stream.Free
end {WriteMemo};
Pages
Now that we have a way to convert record to HTML pages, we also need to think of a unique way to store each record.
Assuming that a database does not hold more than, say 100,000 records (If a table contains more than 100,000 records, then converting the database to HTML pages might not be a good idea in the first place), I can think of a scheme where each record would be in a file called "pag88888.htm", where the 88888 would be the record number in the database.
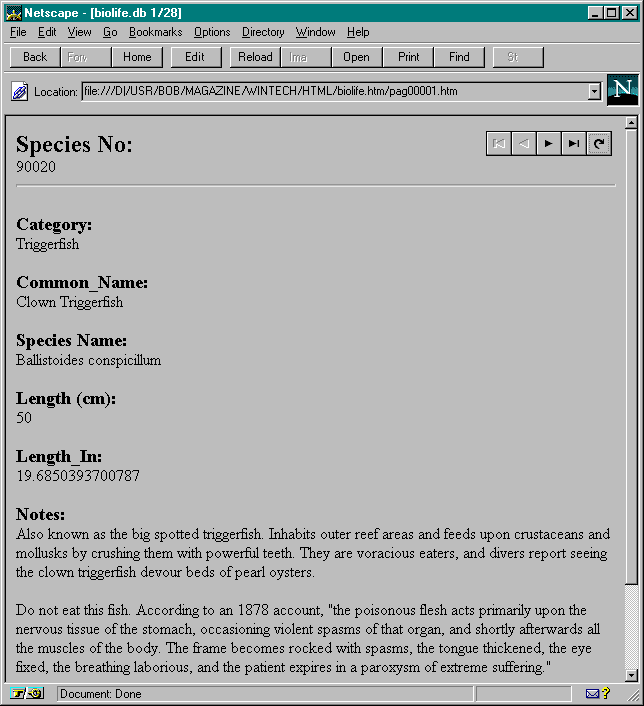
To avoid naming conflicts with other tables, each table would have its own directory (like the BIOLIFE.HTM directory for the BIOLIFE.DB table, so we get BIOLIFE.HTM/PAG00001.HTM for the first record in the BIOLIFE.DB table).
const
FirstPage = 'pag00001.htm';
LastPage: TPageName = 'pag%.5d.htm'; { format }
function PageNr(Nr: Word): TPageName;
begin
Result := Format('pag%.5d.htm',[Nr])
end {PageNr};
Apart from the first page PAG00001.HTM, we also need to know the last page, and a function that can give us the current page number give the record number.
HTML "Live" Buttons
It would be nice to have some kind of way to go from one record to another, and I've used IMAGE MAPs for this purpose.
These are different from the .MAP files that only work when uploaded to a Web Server.
These IMAGE MAPs are embedded within a HTML-page and even work in a browser when loaded as a local file.
The HTML-syntax to display an image is as follows:
<IMG SRC="image.gif">where image.gif is an image file of type .GIF or .JPEG. We can insert options in the image tag such as the name of an image map, like
<IMG SRC="image.gif" USEMAP="#map">Within the page, we can refer to the image map "#map" and in fact talk about the image.gif image. An image map is nothing more than a set of co-ordinates and links. A jump to a link is made when a click occurs within the specified co-ordinate. In HTML-syntax, the image map looks like this for a database navigation bitmap of 25x125 pixels in size:
<MAP NAME="map"> <AREA SHAPE="rect" COORDS="51,0,75,25" HREF="next"> <AREA SHAPE="rect" COORDS="76,0,100,25" HREF="last"> <AREA SHAPE="rect" COORDS="101,0,125,25"HREF="this"> </MAP>The next, last and this are of course the names of other HTML pages, which in this case contain the information for the next, last or current record resp.. That's why we need to know the name of the last page, by the way. And this way, we can simulate our own database navigator!
All I needed now were three bitmaps: one of the database navigator at the first record (first and prior button disabled), one at the last record (last and next button disabled) and only somewhere in the middle of the database (no buttons disables). In each situation, I assign a "link" from one of the buttons to another page. This gives the strong feeling of feedback when clicking on a "button". Of course, the button cannot get clicked down, but we do get fast response, especially when compared to Java or CGI-applications (all that happens is a jump to another static HTML-page).
NAVIGATL.GIF:The Delphi ObjectPascal source code that generates the correct image and image map HTML code for each record is as follows:NAVIGAT.GIF:

if (RecNr = 1) then { first record }
begin
writeln(f,'<IMG SRC="../images/navigatl.gif" '+
'ALIGN=RIGHT USEMAP="#map" BORDER="0">');
writeln(f,'<MAP NAME="map">');
writeln(f,'<AREA SHAPE="rect" COORDS="51,0,75,25" HREF="'+
PageNr(2)+'">');
writeln(f,'<AREA SHAPE="rect" COORDS="76,0,100,25" HREF="'+
LastPage+'">');
writeln(f,'<AREA SHAPE="rect" COORDS="101,0,125,25"HREF="'+
PageNr(RecNr)+'">');
end
else
if (RecNr = RecordCount) then { last record }
begin
writeln(f,'<IMG SRC="../images/navigatr.gif" '+
'ALIGN=RIGHT USEMAP="#map" BORDER="0">');
writeln(f,'<MAP NAME="map">');
writeln(f,'<AREA SHAPE="rect" COORDS="0,0,25,25" HREF="'+
FirstPage+'">');
writeln(f,'<AREA SHAPE="rect" COORDS="26,0,50,25" HREF="'+
PageNr(RecNr-1)+'">');
writeln(f,'<AREA SHAPE="rect" COORDS="101,0,125,25"HREF="'+
PageNr(RecNr)+'">');
end
else { middle record }
begin
writeln(f,'<IMG SRC="../images/navigat.gif" '+
'ALIGN=RIGHT USEMAP="#map" BORDER="0">');
writeln(f,'<MAP NAME="map">');
writeln(f,'<AREA SHAPE="rect" COORDS="0,0,25,25" HREF="'+
FirstPage+'">');
writeln(f,'<AREA SHAPE="rect" COORDS="26,0,50,25" HREF="'+
PageNr(RecNr-1)+'">');
writeln(f,'<AREA SHAPE="rect" COORDS="51,0,75,25" HREF="'+
PageNr(RecNr+1)+'">');
writeln(f,'<AREA SHAPE="rect" COORDS="76,0,100,25" HREF="'+
LastPage+'">');
writeln(f,'<AREA SHAPE="rect" COORDS="101,0,125,25"HREF="'+
PageNr(RecNr)+'">');
end;
writeln(f,'</MAP>');
Having the three navigation images in a shared directory "../images" gives me the chance to convert a lot of tables at the same time that all point to the same three images.
In fact, on our local intranet we now have 23 tables converted this way into over 2,000 HTML pages that all share the same three database navigator bitmap images.
First Results
When converting the BIOLIFE.DB database, consisting of many textual fields, a memo field and one - ignored - image field, we get the following result (note the header which indicated record 1 of 28):
Advanced HTML
Of course, not always does a table consist of textual fields only.
Sometimes, the data in a table is better displayed in a grid or table-like structure.
For that, I need to introduce two new and advanced HTML features: frames and tables.
Frames
Frames are actually a HTML+ extension that is not supported by some web browsers other than those from Netscape or Microsoft.
Frames offer the feature of splitting your web page into two or more pages.
The major big feature about frames is that each sub-page (or frame) can have its own "name" and can jump to other locations.
So, you can have a index or table of contents frame on the left side, for example, and the actual contents in a frame on the right side.
For a table with many records, we can make a list of the key values in the left frame (the main index) and put one page with the contents of one individual record in the right frame.
The key values in the left frame would of course link to an actual page that is displayed in the right frame.
Whenever we click on a link in the main index frame, the right contents frame would show the actual page belonging to the key value(s) we just clicked upon.
Apart from the two frames, we need a special "main" page that defines the number and relative position (and size) of these frames.
I use a left frame names "Menu" that is 32% of the screen width, while the right frame named "Main" has the rest of the screen.
In HTML code, this would look like this:
<HTML> <FRAMESET COLS="32%,*"> <FRAME SRC="pag00000.htm" NAME="Menu"> <FRAME SRC="pag00001.htm" NAME="Main"> </FRAMESET> </HTML>Of course, we can use a sensible title as well (like the name of the table, for example), but I leave that to the reader (and the complete source code).
Tables
Having frames to split the entire contents in an index and single record contents is one thing.
Being able to format the display so it looks like a grid or table is another thing.
HTML 3.0 supports TABLES, which are just about one of the most used features of nowadays HTML pages.
Either with or without borders, tables seem to be used for anything you can't do in a normal way (there's no way to have multi-column contents in a HTML page for example, unless you start using tables).
For our purpose, we want a two-column table with a border.
In the left side we simply display the name of each field, while the right side would contain the value of the field.
Much like the previous text-only solution, only this time we need to change the header codes into table codes.
A <TR> starts a new table row, terminated by </TR>.
The <TD> tag starts a new table field, terminated by </TD>.
The final change is that for each key value, we need to write to the special index HTML page as file (file g in this case).
The updated listing is as follows:
if (keys >= 0) then
begin
writeln(g,'<TR>');
write(g,'<TD><A HREF="../',FileName,'/',PageNr(RecNr),'"TARGET="Main">');
writeln(g,RecNr:3,'</A></TD>')
end;
{ print fields }
writeln(f,'<TABLE BORDER>');
for i:=0 to Pred(FieldCount) do if FieldTypes[i] > sf_UnKnown then
begin
writeln(f,'<TR>');
write(f,'<TD><B>',FieldDefs[i].Name,'</B></TD><TD>');
if FieldTypes[i] = sf_Memo then
writeMemo(f,Fields[i])
else writeln(f,Fields[i].AsString);
writeln(f,'</TD></TR>');
if (keys >= i) then writeln(g,'<TD>',Fields[i].AsString,'</TD>')
end;
if (keys >= 0) then writeln(g,'</TR>');
writeln(f,'</TABLE>');
Final Conversion Result
Having integrated frames and tables in our converter, we can go from a simple BIOLIFE.DB table to a more real-world product table like the PARTS.DB.
This table holds more numerical and less "memo" (or plain text) information, and surely looks better when put in a grid than when formatted with simple headers.
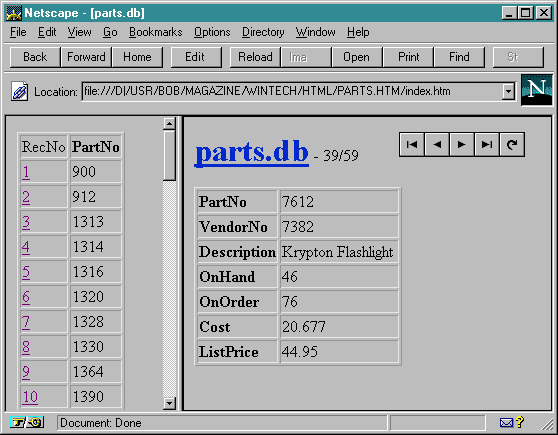
The "live" HTML buttons work just as before, and we can also click on any record number in the index frame on the left. Note that the contents frame on the right even contains the current position (and the total record number) in the table, since this was also generated on the fly.
Now that we have two ways to convert a table to a HTML page, either a simple text convert or a more complex frame/table convert, I've written a little program that uses both. This is a simple console application that needs the name of the table as command-line argument (the table must also be in the current directory). By default, the normal conversion method is used. However, if more than one parameter is supplied, then the frame/table conversion is used (the extra parameters are ignored, by the way).
program BDE2HTML;
{$IFDEF WIN32}
{$APPTYPE CONSOLE}
uses
{$ELSE}
uses WinCrt,
{$ENDIF}
Convert, HTables;
begin
case ParamCount of
0: writeln('Usage: BDE2HTML tablename');
1: Convert.DatabaseHTML('',ParamStr(1));
else HTables.DatabaseHTML('',ParamStr(1))
end
end.
Progress
Converting small tables into a few dozen HTML pages doesn't take a long time; a few seconds at most.
However, converting real big tables to hundreds or thousands of HTML pages (an entire inventory database that needs to be put on the web) may take a few minutes.
For that purpose, I've added a little progress indicator to the Database to HTML converter.
Just a simple form with a TGauge.
We set the MinValue and Value to 0, the MaxValue to the number of records in the table, and after each converted record (and generated HTML page), we increase the Value by one.
A little clock in the upper-left corner tells us how much time is spend already:

Performance
One last difference between a real database application (for example using the BDE) and a database browser consisting of numerous generated HTML pages is performance.
Our "application" does not need any program to run other than the browser.
The data is sent over the network, and the interaction is simulated by image maps and hyper-links.
No BDE or ISAPI/NSAPI program can outperform this architecture.
Of course, we only have static HTML pages, so there's no way to do dynamic search queries or database updates.
For that we do need to develop other things, like CGI scripts.
But our generated static HTML pages can at least "simulate" a Paradox database, even on a Unix Web Server! And especially for database where the contents does not change often (like once a week), this may be a perfect scheme to set up a quick-and-dirty web site and still be able to impress your guests by a database-browser look-and-feel.
Conclusion
In this chapter we've seen a quick-and-dirty way to convert Delphi tables into platform independent HTML pages; either text with headers or in a frame/table format.
We've learned how to apply HTML techniques, including image maps, to simulate "live" buttons and actions.
These techniques have proven to be very useful in internet as well as intranet applications (at least for me), and result in faster performance than any other approach (a limitation may be server space if you have a real big number of HTML pages - but that would mean a big "real" database as well, of course).
What's left now (as an example to the readers) is support for database images, and additional queries (for example to generate master-detail HTML pages).


